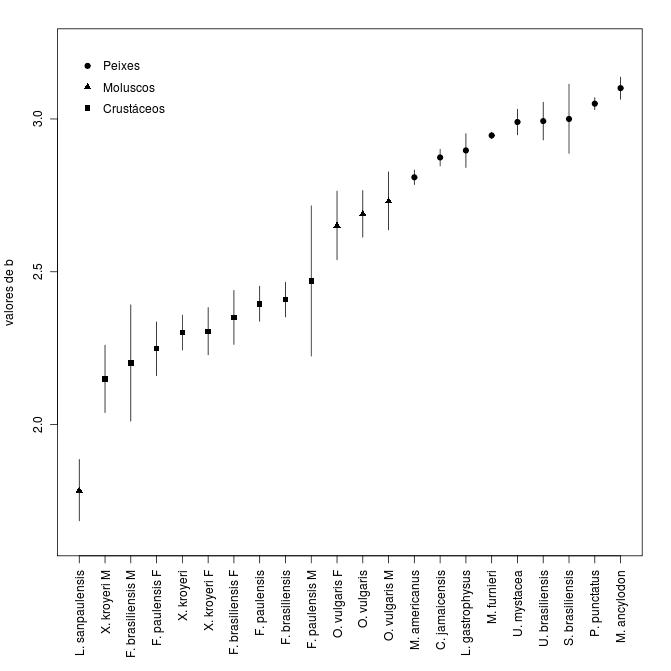
Este gráfico mostra os valores de b (coeficiente angular) e seus intervalos de confiança calculados para diversas espécies. Para melhor vizualização as espécies são ordenadas pelo valor de b e diferentes grupos (peixes, moluscos e crustáceos) são identificados com símbolos especícicos.
| SP | GRP | b | ICi | ICs |
| S. brasiliensis | P | 3,000 | 2,887 | 3,114 |
| U. brasiliensis | P | 2,993 | 2,931 | 3,055 |
| U. mystacea | P | 2,990 | 2,948 | 3,032 |
| L. gastrophysus | P | 2,897 | 2,841 | 2,952 |
| C. jamaicensis | P | 2,874 | 2,846 | 2,901 |
| M. ancylodon | P | 3,101 | 3,064 | 3,137 |
| M. americanus | P | 2,809 | 2,785 | 2,833 |
| M. furnieri | P | 2,946 | 2,935 | 2,957 |
| P. punctatus | P | 3,050 | 3,030 | 3,070 |
| L. sanpaulensis | M | 1,784 | 1,685 | 1,886 |
| O. vulgaris | M | 2,689 | 2,613 | 2,766 |
| O. vulgaris F | M | 2,651 | 2,539 | 2,764 |
| O. vulgaris M | M | 2,731 | 2,637 | 2,827 |
| F. brasiliensis | C | 2,409 | 2,352 | 2,466 |
| F. brasiliensis F | C | 2,350 | 2,262 | 2,439 |
| F. brasiliensis M | C | 2,201 | 2,011 | 2,392 |
| F. paulensis | C | 2,395 | 2,338 | 2,453 |
| F. paulensis F | C | 2,248 | 2,160 | 2,336 |
| F. paulensis M | C | 2,470 | 2,224 | 2,716 |
| X. kroyeri | C | 2,301 | 2,244 | 2,358 |
| X. kroyeri F | C | 2,305 | 2,228 | 2,383 |
| X. kroyeri M | C | 2,149 | 2,039 | 2,260 |
# carregando e verificando dados
rm(list=ls())
dat.bvar <- read.delim("clipboard",dec=",")
summary(dat.bvar)
SP GRP b ICi ICs
C. jamaicensis : 1 C:9 Min. :1.784 Min. :1.685 Min. :1.886
F. brasiliensis : 1 M:4 1st Qu.:2.316 1st Qu.:2.232 1st Qu.:2.404
F. brasiliensis F: 1 P:9 Median :2.670 Median :2.576 Median :2.765
F. brasiliensis M: 1 Mean :2.607 Mean :2.527 Mean :2.686
F. paulensis : 1 3rd Qu.:2.934 3rd Qu.:2.877 3rd Qu.:2.956
F. paulensis F : 1 Max. :3.101 Max. :3.064 Max. :3.137
(Other) :16
C. jamaicensis : 1 C:9 Min. :1.784 Min. :1.685 Min. :1.886
F. brasiliensis : 1 M:4 1st Qu.:2.316 1st Qu.:2.232 1st Qu.:2.404
F. brasiliensis F: 1 P:9 Median :2.670 Median :2.576 Median :2.765
F. brasiliensis M: 1 Mean :2.607 Mean :2.527 Mean :2.686
F. paulensis : 1 3rd Qu.:2.934 3rd Qu.:2.877 3rd Qu.:2.956
F. paulensis F : 1 Max. :3.101 Max. :3.064 Max. :3.137
(Other) :16
# reorganizando a tabela de dados
order(dat.bvar$b) # linhas em ordem crescente de b
order(dat.bvar$b) # linhas em ordem crescente de b
[1] 10 22 16 18 20 21 15 17 14 19 12 11 13 7 5 4 8 3 2 1 9 6
rank(dat.bvar$b) # posição de cada linha quando ordenada por b
[1] 20 19 18 16 15 22 14 17 21 1 12 11 13 9 7 3 8 4 10 5 6 2
[1] 20 19 18 16 15 22 14 17 21 1 12 11 13 9 7 3 8 4 10 5 6 2
dat.bvar$RAN <- rank(dat.bvar$b)
levels(dat.bvar$SP) # níveis de SP
[1] "C. jamaicensis" "F. brasiliensis" "F. brasiliensis F"
[4] "F. brasiliensis M" "F. paulensis" "F. paulensis F"
[7] "F. paulensis M" "L. gastrophysus" "L. sanpaulensis"
[10] "M. americanus" "M. ancylodon" "M. furnieri"
[13] "O. vulgaris" "O. vulgaris F" "O. vulgaris M"
[16] "P. punctatus" "S. brasiliensis" "U. brasiliensis"
[19] "U. mystacea" "X. kroyeri" "X. kroyeri F"
[22] "X. kroyeri M"
levels(dat.bvar$SP) # níveis de SP
[1] "C. jamaicensis" "F. brasiliensis" "F. brasiliensis F"
[4] "F. brasiliensis M" "F. paulensis" "F. paulensis F"
[7] "F. paulensis M" "L. gastrophysus" "L. sanpaulensis"
[10] "M. americanus" "M. ancylodon" "M. furnieri"
[13] "O. vulgaris" "O. vulgaris F" "O. vulgaris M"
[16] "P. punctatus" "S. brasiliensis" "U. brasiliensis"
[19] "U. mystacea" "X. kroyeri" "X. kroyeri F"
[22] "X. kroyeri M"
dat.bvar$SP<-ordered(dat.bvar$SP, levels=dat.bvar$SP[order(dat.bvar$b)]) # reordena SP pela ordem de b
levels(dat.bvar$SP) # níveis de SP reordenados
levels(dat.bvar$SP) # níveis de SP reordenados
[1] "L. sanpaulensis" "X. kroyeri M" "F. brasiliensis M"
[4] "F. paulensis F" "X. kroyeri" "X. kroyeri F"
[7] "F. brasiliensis F" "F. paulensis" "F. brasiliensis"
[10] "F. paulensis M" "O. vulgaris F" "O. vulgaris"
[13] "O. vulgaris M" "M. americanus" "C. jamaicensis"
[16] "L. gastrophysus" "M. furnieri" "U. mystacea"
[19] "U. brasiliensis" "S. brasiliensis" "P. punctatus"
[22] "M. ancylodon"
ord.sp<-dat.bvar$SP[order(dat.bvar$b)]
[4] "F. paulensis F" "X. kroyeri" "X. kroyeri F"
[7] "F. brasiliensis F" "F. paulensis" "F. brasiliensis"
[10] "F. paulensis M" "O. vulgaris F" "O. vulgaris"
[13] "O. vulgaris M" "M. americanus" "C. jamaicensis"
[16] "L. gastrophysus" "M. furnieri" "U. mystacea"
[19] "U. brasiliensis" "S. brasiliensis" "P. punctatus"
[22] "M. ancylodon"
ord.sp<-dat.bvar$SP[order(dat.bvar$b)]
# criando o gráfico
attach(dat.bvar)
par(mar=c(8,4,2,2))
plot(c(1:nrow(dat.bvar)),rep(3,nrow(dat.bvar)),ylab="valores de b",xlab="",ylim=c(min(ICi)*0.97,max(ICs)*1.03),type="n",xaxt="n")
axis(1,1:nrow(dat.bvar),labels=ord.sp,las=2)
for (i in 1:length(ord.sp)){
segments(i,ICi[SP==ord.sp[i]],i,ICs[SP==ord.sp[i]])
}
points(RAN[GRP=="P"],b[GRP=="P"],pch=19)
points(RAN[GRP=="M"],b[GRP=="M"],pch=17)
points(RAN[GRP=="C"],b[GRP=="C"],pch=15)
legend(locator(1),bty="n",c("Peixes","Moluscos","Crustáceos"),pch=c(19,17,15)) # clique no gráfico para indicar o local da legenda
par(mar=c(8,4,2,2))
plot(c(1:nrow(dat.bvar)),rep(3,nrow(dat.bvar)),ylab="valores de b",xlab="",ylim=c(min(ICi)*0.97,max(ICs)*1.03),type="n",xaxt="n")
axis(1,1:nrow(dat.bvar),labels=ord.sp,las=2)
for (i in 1:length(ord.sp)){
segments(i,ICi[SP==ord.sp[i]],i,ICs[SP==ord.sp[i]])
}
points(RAN[GRP=="P"],b[GRP=="P"],pch=19)
points(RAN[GRP=="M"],b[GRP=="M"],pch=17)
points(RAN[GRP=="C"],b[GRP=="C"],pch=15)
legend(locator(1),bty="n",c("Peixes","Moluscos","Crustáceos"),pch=c(19,17,15)) # clique no gráfico para indicar o local da legenda
detach(dat.bvar)